Ceci est une mise à jour de l’article original. Elle date du 2018-12-27.
Pas de raccourci pour apprendre
Quand j’ai commencé à écrire ce post, j’étais très confiant dans le fait que ce serait rapide. Après tout, j’avais toutes les ressources nécessaires à ma disposition, un tas de codes que j’avais passé des mois à écrire. C’était censé être une affaire de copier-coller. J’avais tort. Vous voyez, encore une fois, j’ai sous-estimé le pouvoir du monstre en moi que je veux toujours bien faire les choses tout le temps. Comprenez-moi bien. C’est toujours une bonne chose pour une personne de vouloir être la meilleure version d’elle-même et de donner le meilleur de soi. Dans mon cas, malheureusement, cette ligne semble toujours s’éloigner quand je m’en approche (je peux seulement imaginer la tête de certains de mes amis quand ils liront ça). Ce post n’a pas été une exception à la règle.
J’apprenais encore ggplot2 quand l’idée de ce projet de data science est apparue. Pour être honnête, je dirais que j’étais encore dans ma phase lune de miel. Je ne pouvoir tout simplement en avoir assez de ggplot2. Donc, ça semblait juste naturel de l’utiliser pour le projet. Au début, les documents que je produisais étaient des fichiers pdf. Donc, je n’avais aucune raison de penser au-delà de ggplot2. Ensuite, l’idée de ce blog est venue et j’ai réalisé que la visualisation intéractive serait une meileure approche. Je devais choisir un package. Trois options s’offraient à moi: ggvis, plotly et shiny.
J’avais un penchant fort pour ggvis, sur lequel j’avais pris des cours en ligne. J’avais beaucoup aimé. C’était tout simplement une suite logique de ggplot2. A part les quelques éléments auxquels je devais m’ajuster (remplace + par %>%, = par =~ ou :=, geom par layers, etc.), je me sentais dans mon élément. Malheureusement, je package est actuellemet dormant. Ceci m’a un peu découragé.
Donc, j’ai considéré la seconde option: shiny. J’avais testé les eaux avec ce package aussi. Mais just testé! J’ai connaissais les éléments basiques, mais pas assez pour être confiant dans ma capacité à mener un projet avec l’outil. Je n’ai acquis une maîtrise de tous les détails concernant l’interface d’utilisateur et le server. Avec ce que je connaissais de ggplot2, just un peu plus d’effort m’aurait permis d’aller avec shiny, mais je ne voulais pas m’embarquer dans un long processus d’apprentissage. Donc, je suis passé sur cette option aussi.
Ensuite, est venue la troisième option: plotly. Celle-ci avait attiré mon attention depuis longtemps, bien avant que je me rabiboche avec R, mais j’étais intimidé. Je me suis dit qu’il serait compliqué d’apprendre ça aussi (comme pour shiny…vous remarque une récurrence là?) Aussi, je commençais à me sentir trop à la l’aise avec le peu que j’avais appris de ggplot2. Dans mon esprit, j’aurai pu passer toute une vie sans avoir besoin de plotly. Un seul détail m’a fait reconsidérer ma position: ggplotly. Réaliser que je pouvais créer un objet avec ggplot2, le passer à ggplotly et avoir un objet plotly, c’était tout simplement - comme le diraient les adolescents - ‘hallucinant’ (ne dites pas que je suis déjà dépassé sur ça). Mais, malheureusement, j’ai atteint la limite de la fonction. Elle ne me restituait pas tout dans plotly. Certains détails étaient perdus, comme les titres et les sous-titres.
Au final, je me retrouvais dans un position difficile. Avec ggplot2, j’allais râter les joies de la visualisation intéractive. Avec ggplot + plotly, j’allais perdre certains détails qui contribuent à la grandeur de ggplot2. Avec shiny + un de ces deux, j’allais devoir apprendre beaucoup. J’ai passé des jours à peser mes options, faisant des va-et-vients entre mes codes, espérant que j’allais pouvoir me frayer un raccourci. Je n’ai pas pu. Je savais une chose à coup sûr. ggvis n’étais pas une option viable. Contrairement à plotly ou shiny, ggvis n’était pas sous maintenance et développement. Pour tout ce que je savais, il pouvait bien se trouver dans sa tombe (j’ai tellement peur de cette idée que j’en ai de frissons rien qu’à y penser), ou peut-être prenait-il une longue sieste de laquelle il fera un grand retour (comme une momie…enfin une bonne…comme les films du début des années 2000…pas le récent là…désolé M. Cruise…je suis toujours fan de la franchi M.I.). J’ai fini par penser de longues heures à regarder des vidéos sur Youtube (qui est maintenant l’espace où je vais pour apprendre plutôt que de découvrir les dernières vidéos clips, comme dans le bon vieux temps…ça me manque ces vieux jours) et à naviguer sur les sites donnant des tutoriels sur plotly et shiny dans R. Je n’y suis toujours pas arrivé, au point où je peux dire que je maîtrise la chose. Mais j’ai compris quelques astuces. De façon générale, j’ai seulement chercher à traduire mes anciens codes ggplot2 en visualisations intéractives développées dans shiny.
Ce que j’ai appris de l’expérience d’écriture de ce post, c’est qu’il n’y a pas de racccourci quand il s’agit d’apprendre et rien n’est jamais perdu (hum…ça sonne profond ça…notez ça et marquez ma tombe quand je serai parti). Ce projet m’a permis de comprendre les outils mentionnés dessus plus qu’aucun tutoriel que j’ai pris en ligne. Probablement parce que j’étais moins préoccupé à reproduire ce que j’avais sous le yeux qu’à essayer de comprendre mes données à travers la visualisation.
Ce post était initiallemet censé être une simple mise à jour de code précédemment écris. A la fin, ce fut un épisode centré sur shiny/plotly dans une saison concentrée sur les incidents (si vous êtes/étiez un fan de Lost, vous comprendrez):
J’ai appris à :
faire une application shiny avec plotly (ggplot2, la distance renforce les liens du coeur…je te reviendrai);
publier une application shiny: je me suis ouvert un compte shiny (gratuitement…efin, pour le moment) et j’ai failli perdre les esprits lors du processus de déploiement (j’allais d’échec en échec); et
insérer une application shiny dans un post de blog.
Je suis presque sûr que j’ai poussé quelques cheveux blancs durant derniers jours, mais ça en valait le coup.
La visualisation intéractive
Le long de l’écriture ce post, j’ai réalisé que je me voulais pas autant de graphiques que j’en avais sur les premiers fichiers pdf que j’avais produits. Et avec les outils de visualisation intéractive comme shiny et plotly, je pouvais éviter. Et avec la limitation du nompbre d’applications sur un compte shiny, je ne pouvais pas de toute façon (et oui…j’ai pris la formule grauite, comme toujours). En final, j’avais toutes les incitations au monde pour être aussi créatif que je le pouvais. Considérant les contraintes avec lesquelles je devais faire, j’avais besoin de visualisations qui se prêteraient à plusieurs requêtes de la part de l’utilisation, qui premettraient de fournir diverses sortes d’information sans voir leur nature altérer. Jusque là, j’ai créée trois appris que j’ai assez aimé (pour partager).
Exploration des attributs des incidents
Selon la transformation choisie, la liste de départ peut soit être organisée en données de panel ou en série temporelle. Pour faire simple, je me suis tourné vers le second choix - optant pour une agrégation mensuelle - et, pour l’accompagner, des barres (barplot).
Ceci semblait être la meilleure façon d’explorer les attributs des incidents. Pour l’application, j’ai choisi quatre variables:
le nombre: un simple compte du nombre d’incidents ;
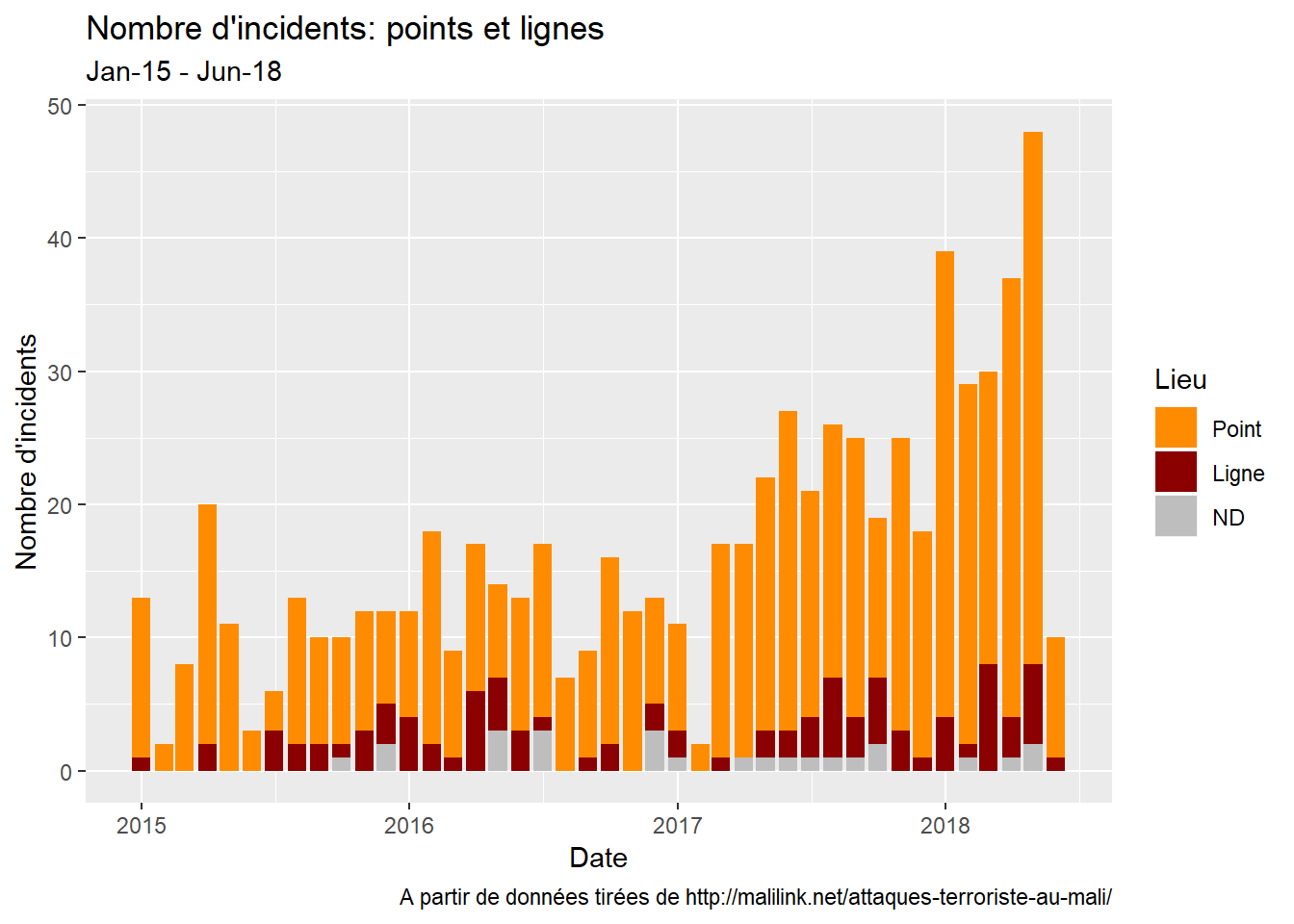
le lieu: comme indiqué dans les posts précédents, je distingue entre les incidents qui ont eu lieu en un point connu - c’est à dire dont les coordonnées sont connues - et ceux pour lesquels ces détails ne sont pas fournis. Seuls les points entre lesquels ils ont eu lieu sont connus. Ceci crée une dichotomy, points contre lignes, que j’ai trouvé utilise de représenter ;
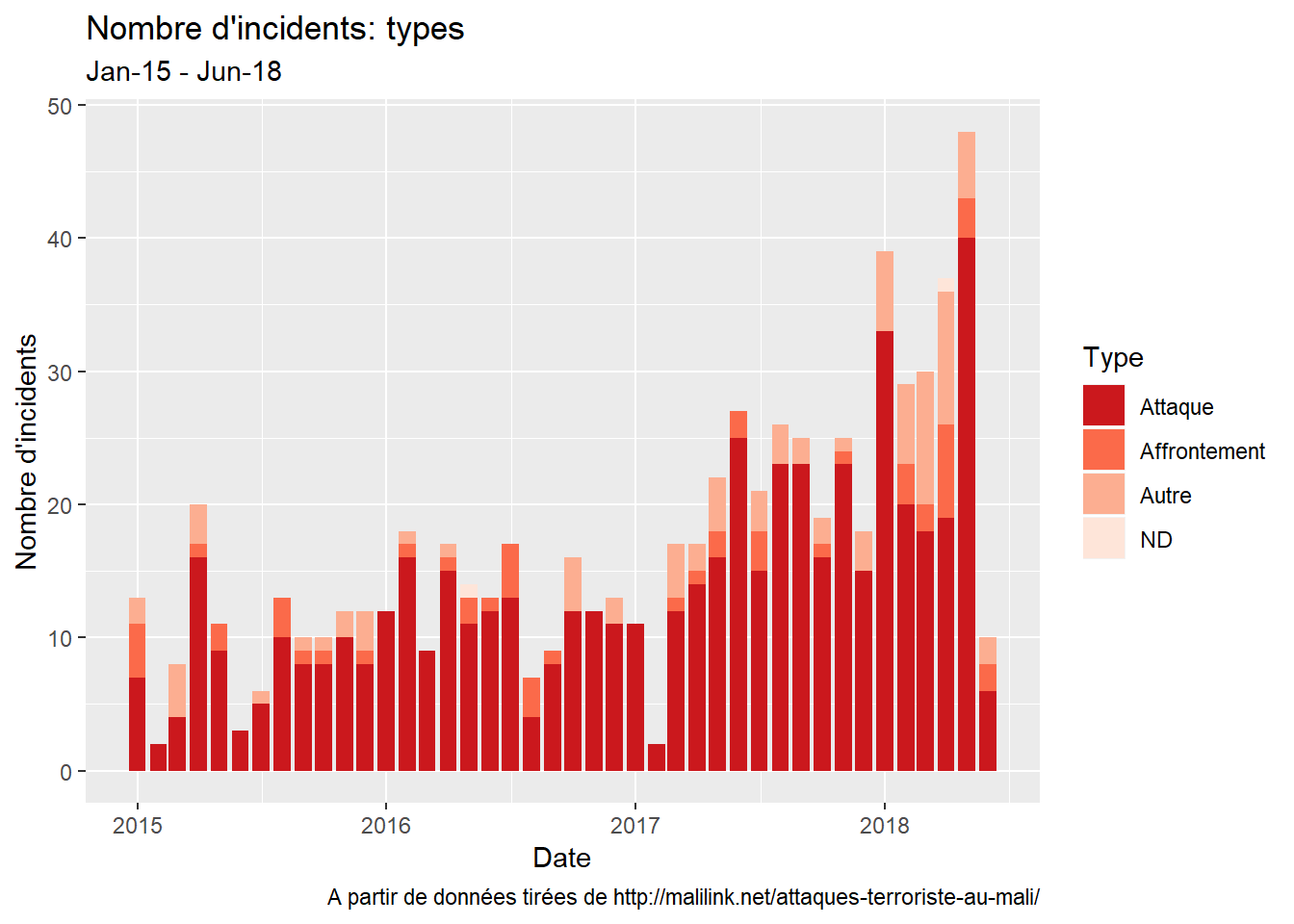
le type: cette variable indique si l’incident est une attaque d’une organisation armée (terroriste ou non), un affrontement entre communautés (groupes ethiques), ou de nature différente (tout le reste) ;
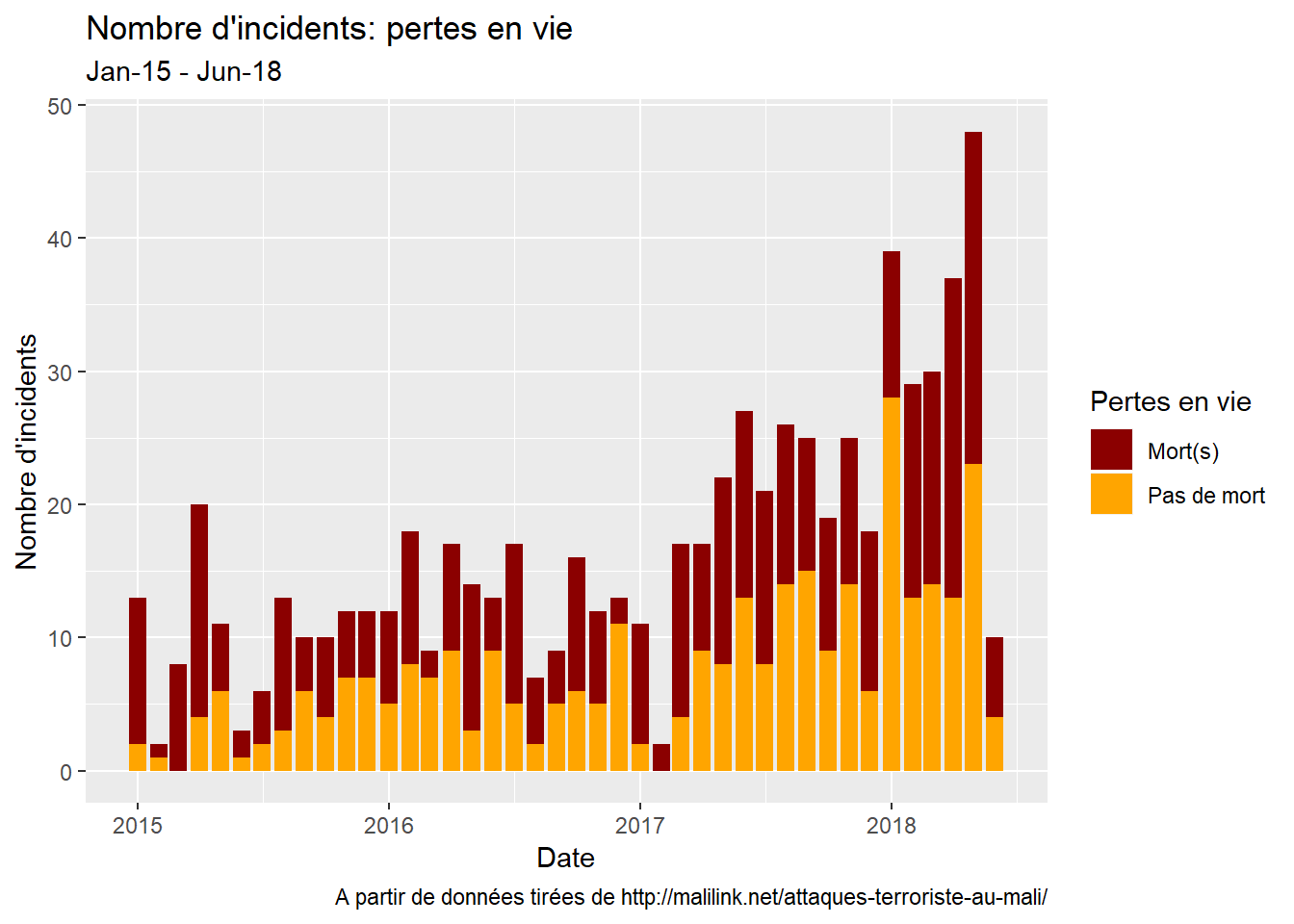
la violence de l’incident (pertes en vies): cette variable montre s’il y a eu des pertes en vies humaines, indépendamment de la partie qui en a souffert. J’ai pensé que prendre en compte l’identité des victimes serait - en tout cas pour l’instant - au-delà de la simple observation, ce pour quoi je ne me sens pas pleinement équipé.
Un aperçu des principales variables à travers le temps
Après l’exploration de plusieurs autres visualisation, j’ai décidé de me focaliser - du moins, pour cette phase - sur trois variables :
les incidents;
les morts; et
les bléssés.
Je me suis dit qu’il serait intéressant de regarder les cumuls:
depuis le début des séries, qui est de 2015 (celà aurait été très utile d’avoir une série qui remontait jusqu’à 2012) ;
par an
Le résultat est présenté ci-bas:
Ajout d’une dimension spatiale
Utilisant les mêmes noms de variables, j’ai ajouté une carte intéractive pour représenter les cumuls annuel de chaque.
Le bon vieux ggplot2…just au cas où
Quelques mois se sont écoulés entre la première version de ce post à la réécriture qui commence ici.
Après d’innombrables visites sur ce post, j’ai réalisé que les applications shiny ne marchaient pas toujours. Hé, que puis-je dire ? C’est le prix à payer quand on veut du gratuit! Enfin bref…j’ai décidé de retourner à mon ancienne flamme - ce bon vieux ggplot2 - et d’inclure quelques graphiques pour avoir quelque chose à regarder au où les applications shiny ne seraient pas disponibles.
Les incidents
Retournons un instant aux incidents.
Après un regard d’ensemble (les volumes mensuels)…
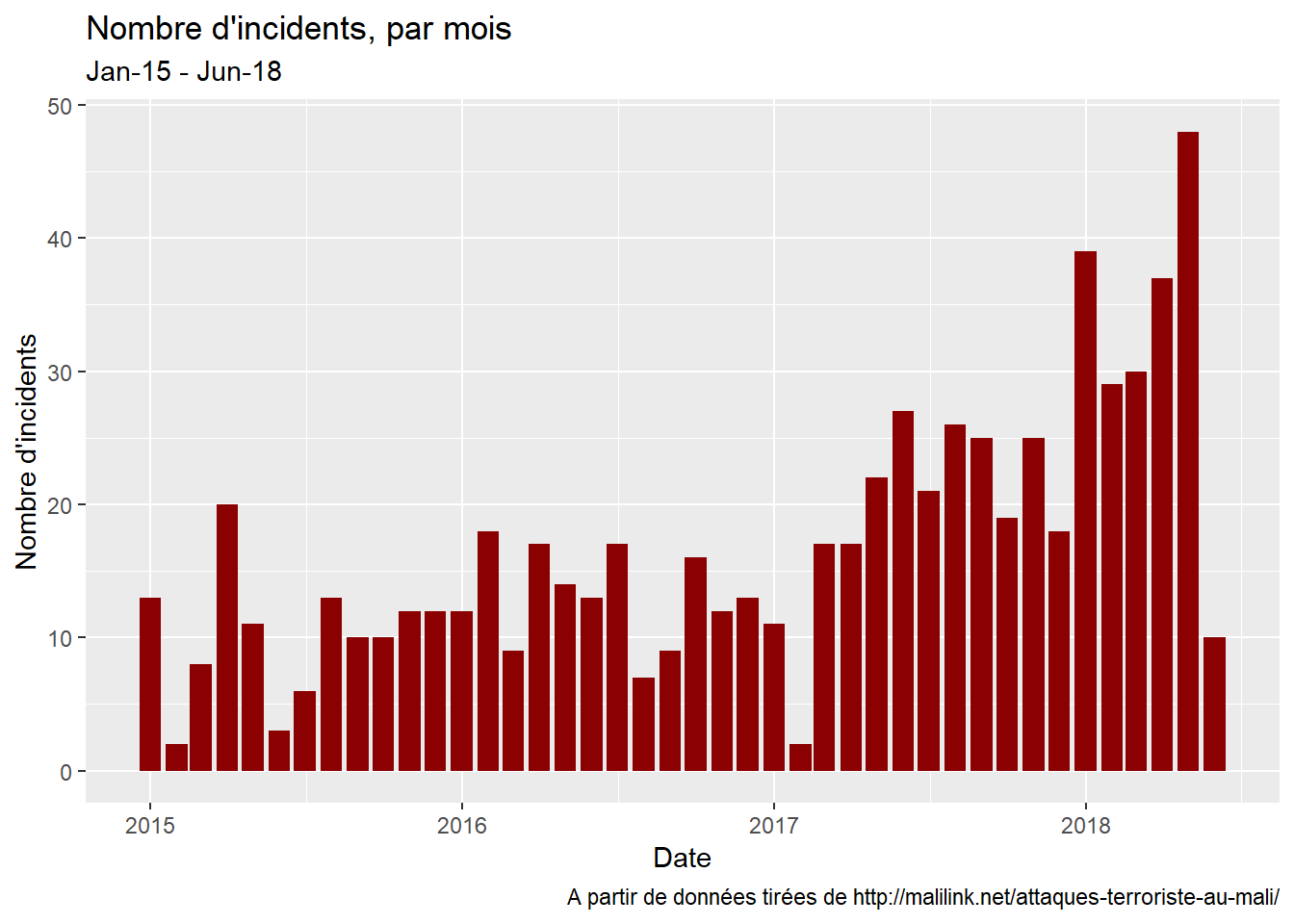
…nous allons décomposer sur la base de diverses variables: le lieu…
…le type…
…et la pertie de vie(s) humaine(s).
Les cumuls
Comme précédemment, nous allons explorer les cumuls des incidents eux-mêmes…
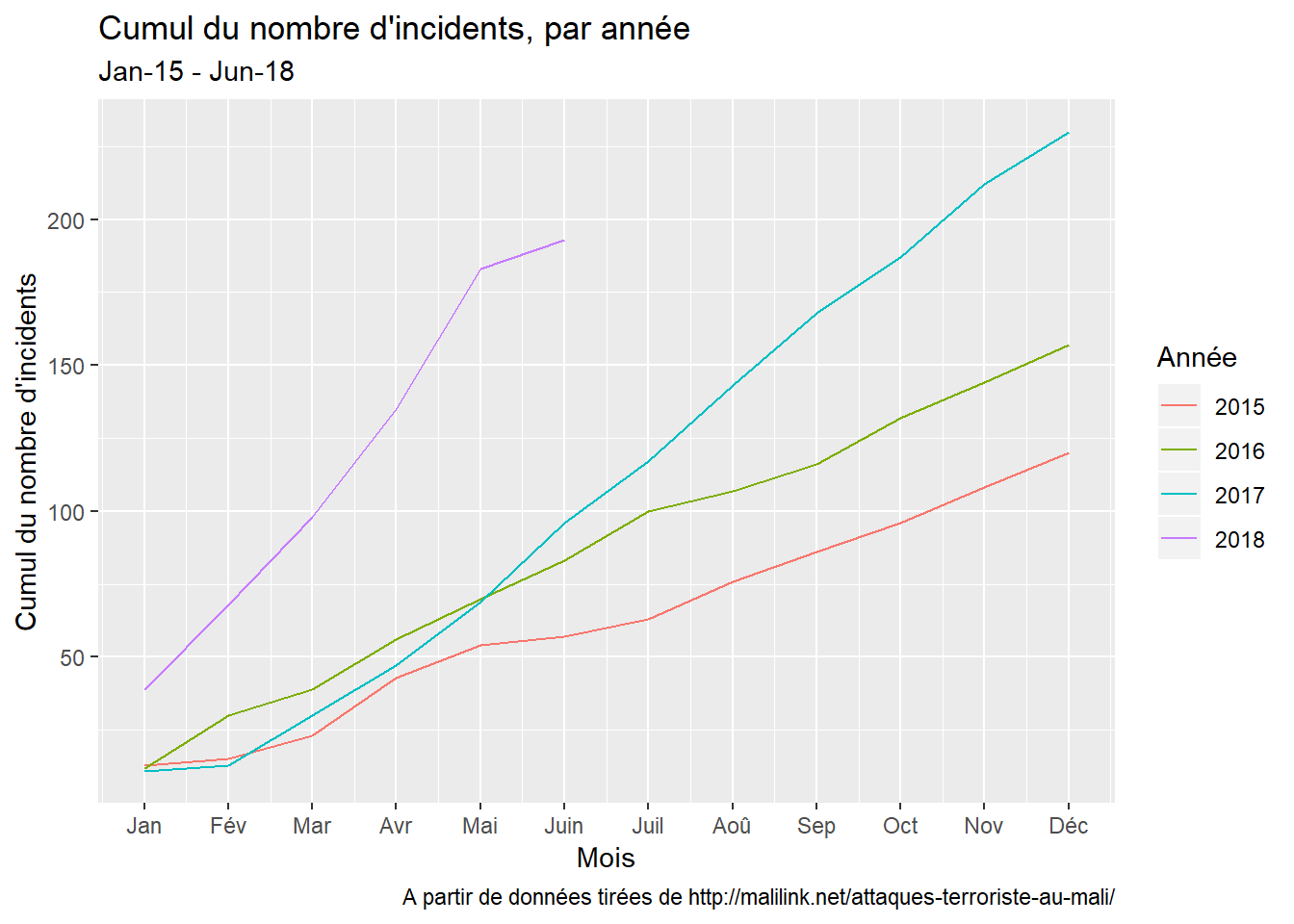
…et des victimes qu’ils font.
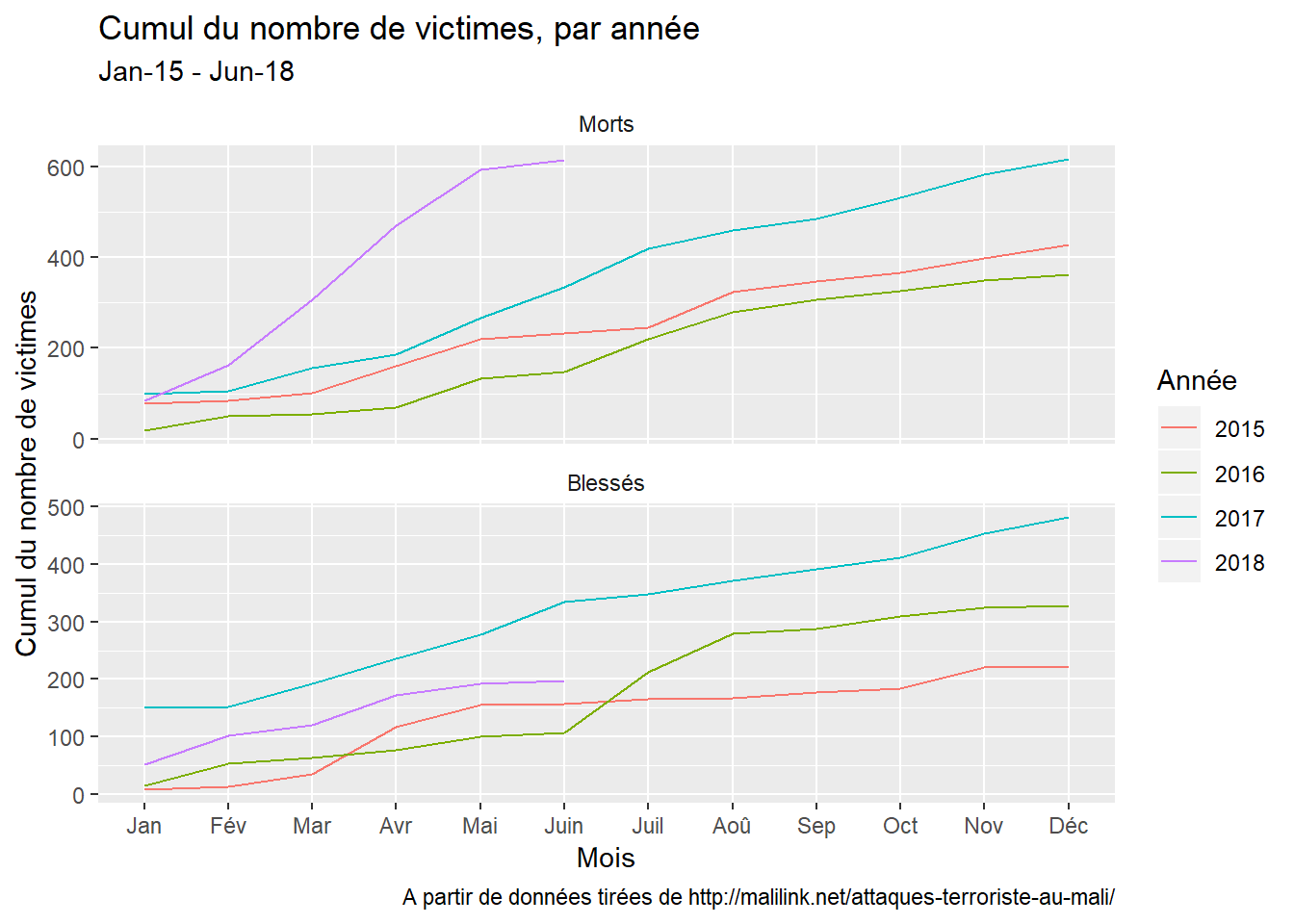
La réécriture de cet article montre que souvent, il faut s’éloigner de quelqu’un ou de quelque chose pour réellement en connaitre la valeur. J’espère que ceci servira de lesson à tous ceux qui pensent à rompre avec quelqu’un ou quelque chose. Mot de fin: désolé ggplot2.
Malgré le ton léger utilisé, je sais que la situation est très préoccupante dans mon pays, le Mali. Je prie pour que la situation s’améliore. Et j’espère que l’examen des données nous y aidera.